Mavera Platform
Make high-stakes decisions with receipts. Mavera turns live signals into market proof — a Listen / Decide / Make / Measure platform built for leaders who need more than generic AI. A synthetic audience engine blends generative models with live context, simulating audience reactions before budget is committed and producing explainable, defensible insight (research benchmarked at 98% agreement with Harvard's OASIS human-subject study). Under the hood: 95+ database models, 100+ API routes, 40+ Plate editor plugins, and 15+ third-party integrations spanning conversational AI, document generation, meeting intelligence, focus groups, video analysis, and news digestion.
- Next.js 14
- React
- TypeScript
- Tailwind CSS
- Radix UI
- Prisma
- PostgreSQL
- Auth0
- Zustand
- Jotai
- Plate (Udecode) v44
- Vercel AI SDK
- OpenAI GPT-5
- Trigger.dev v4
- Stripe
- Resend
- AWS S3 + CloudFront
- Recall.ai
- Tavus
- RunwayML
- Replicate
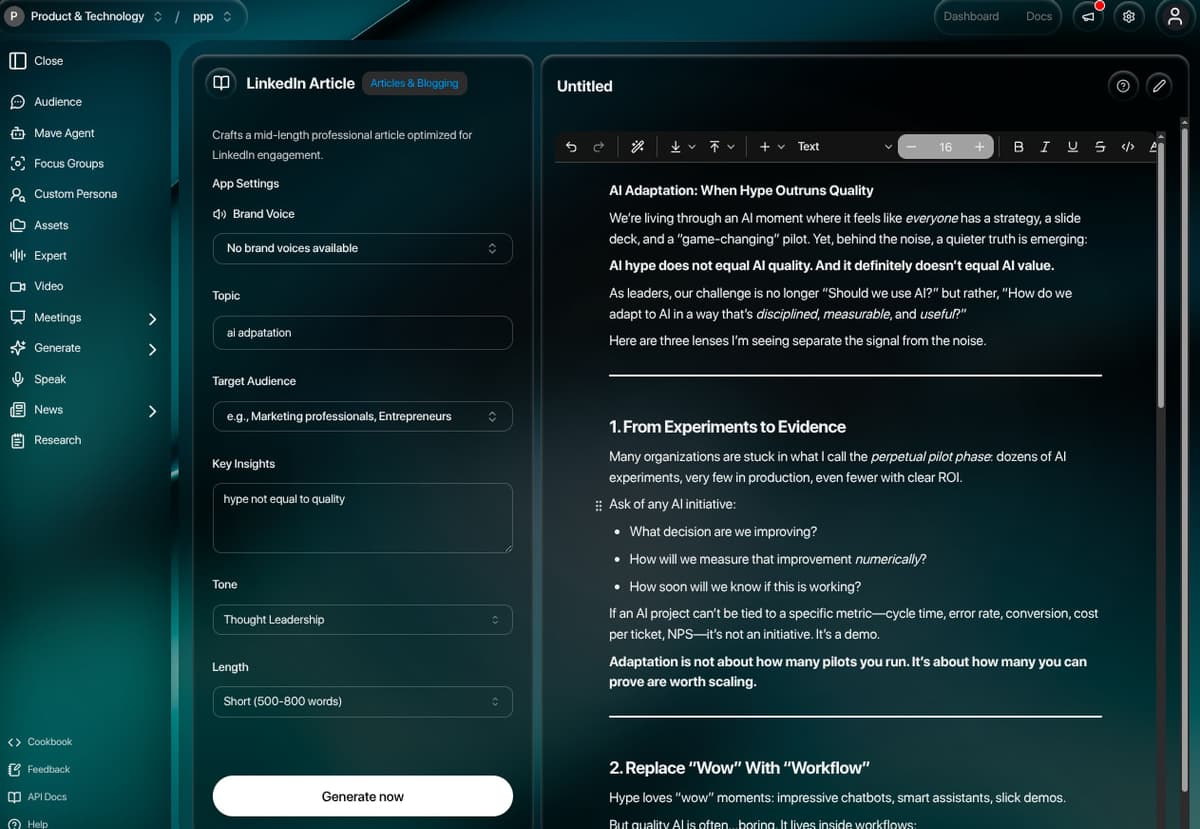
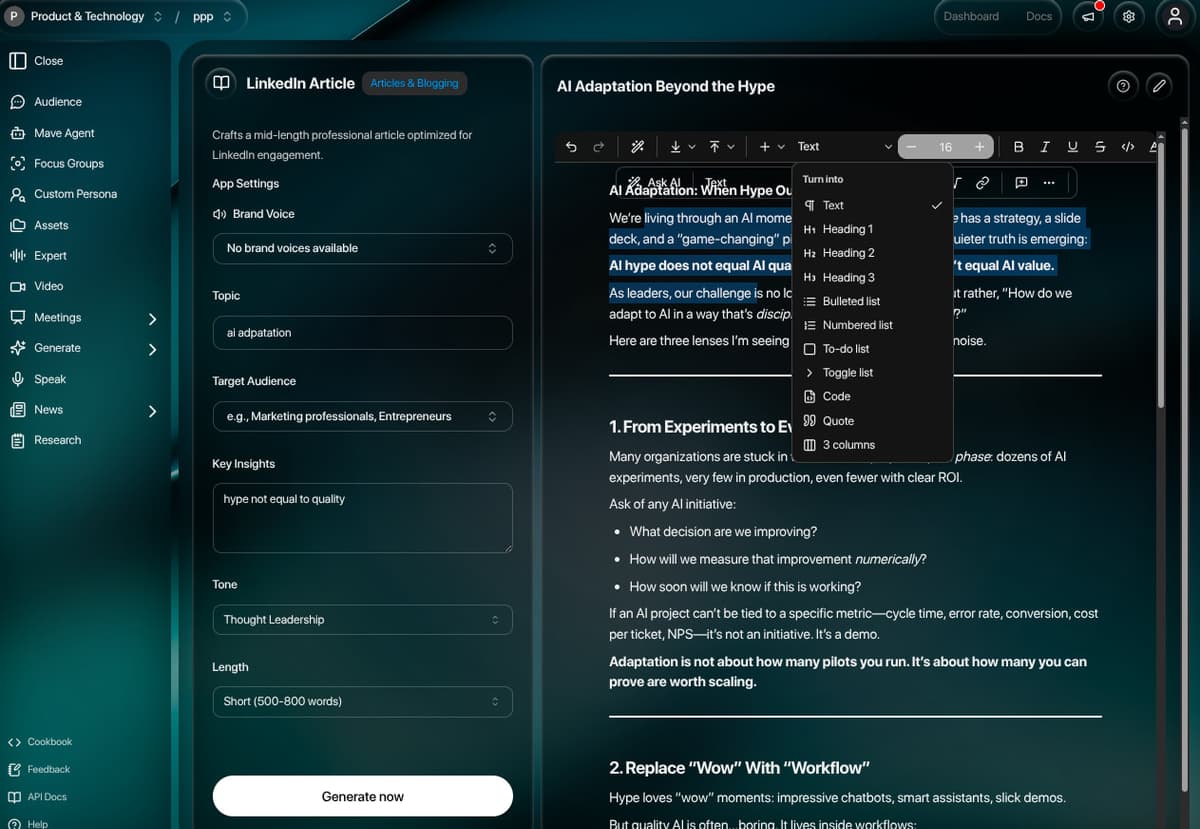
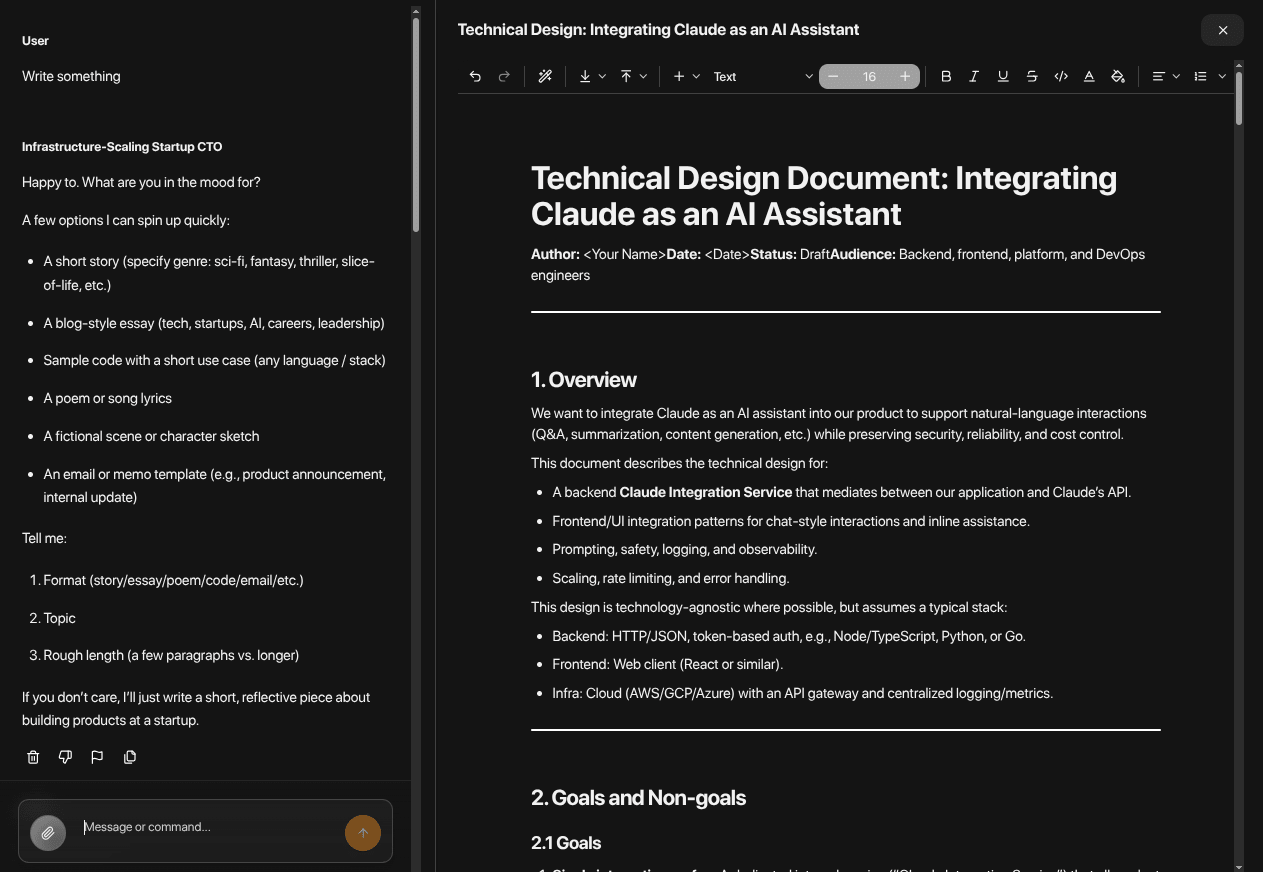
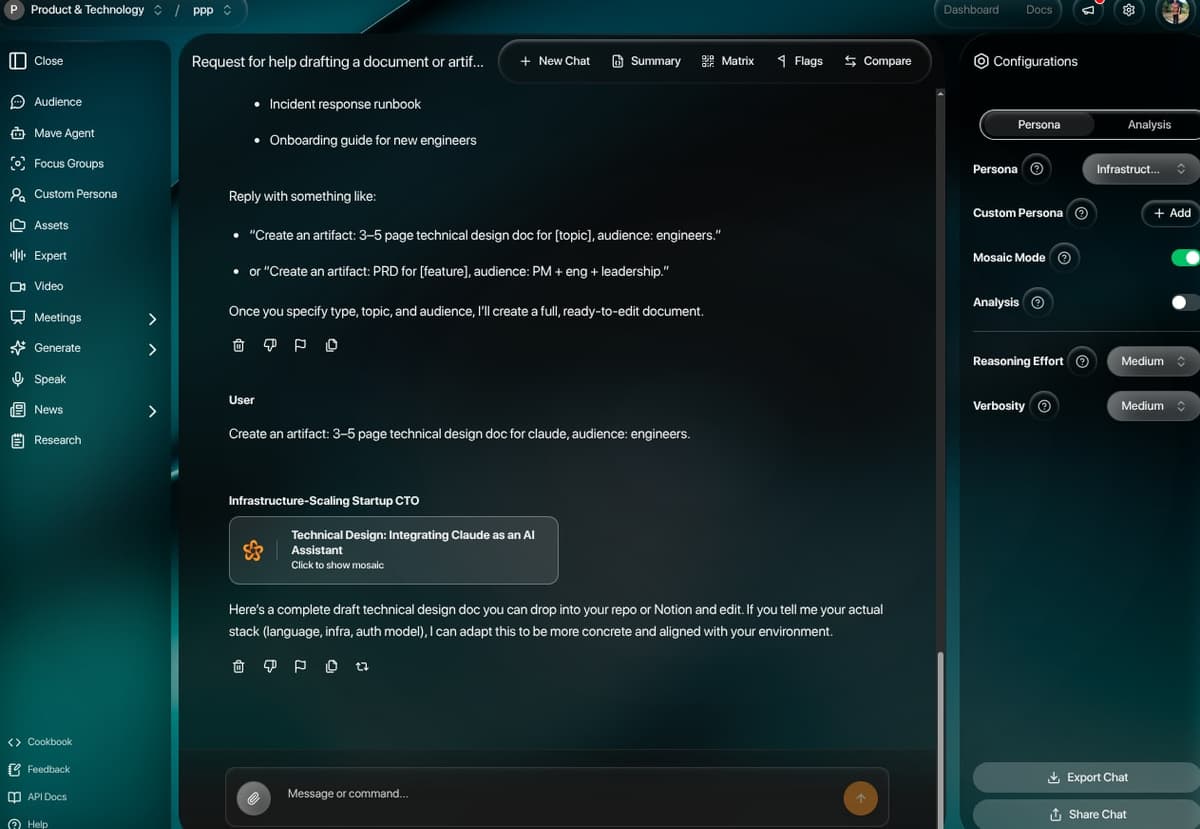
How I framed it.
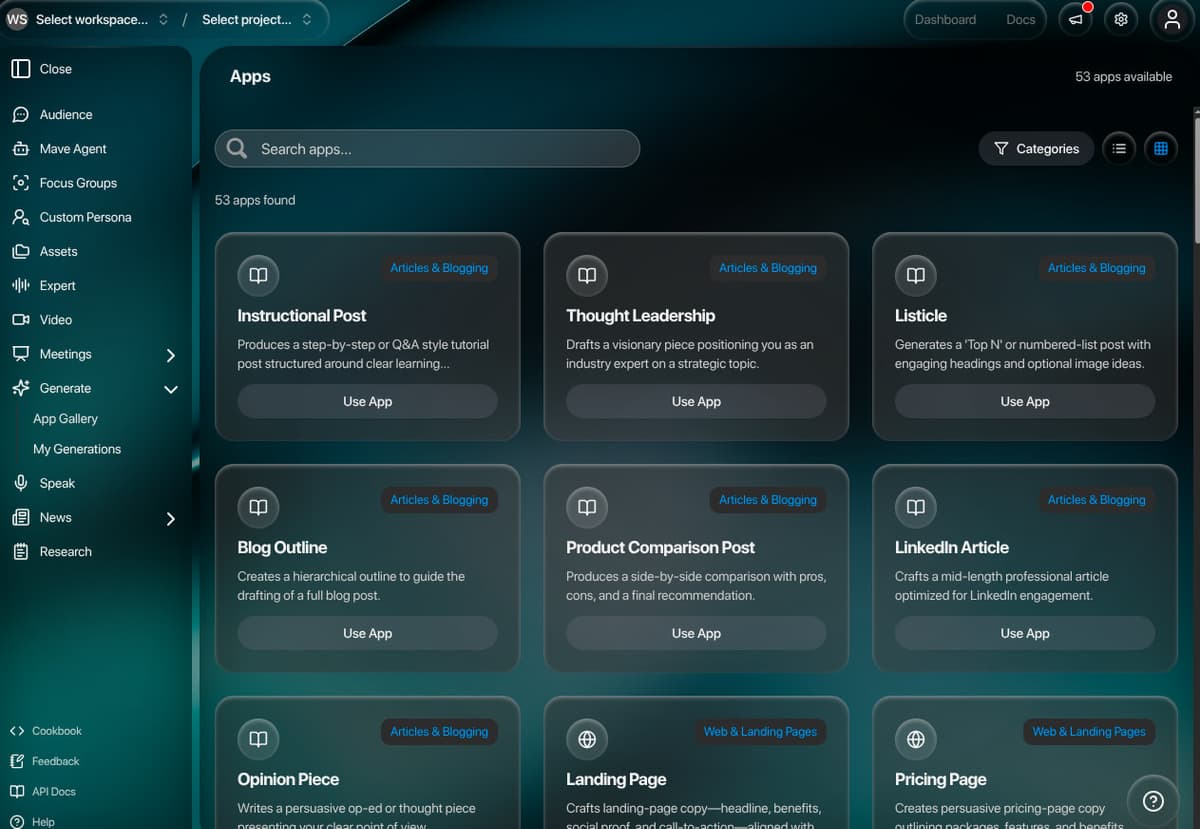
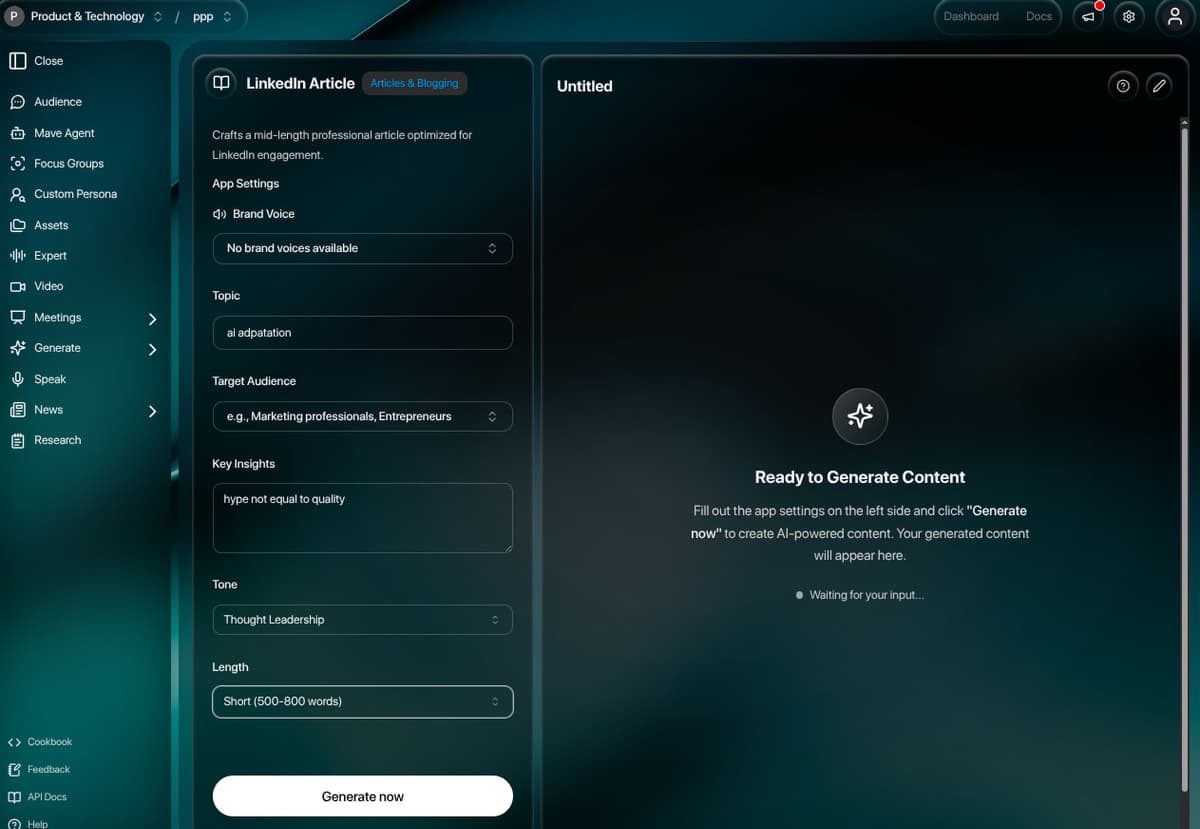
Mavera (mavera.io) is a production AI research and insights platform organized around a four-pillar framework — Listen (stream signals that impact success), Decide (simulate audience reactions before committing budget), Make (create work that connects now and is defensible later), and Measure (study impact while there's still time to adjust). The synthetic audience engine blends generative models with live context to handle complex, sensitive conversations where accuracy and accountability matter, with transparent reasoning and traceable evidence on every output (98% agreement with Harvard's OASIS human-subject study). The platform consolidates seven heavyweight workflows into a single workspace: persona-based conversational AI, AI-streamed document generation through editable templates, meeting intelligence powered by Recall.ai with AI-extracted highlights and tasks, structured focus groups with 11 question types, frame-by-frame video analysis, scheduled news digests with persona-specific perspectives, and the Mave agent for branched, evidence-tracked research. The system spans 95+ Prisma models, 100+ API routes, 61 server-action files, 40+ Plate editor plugins, and 15+ third-party integrations — delivered as a multi-tenant Next.js 14 App Router application running on PostgreSQL, AWS, and Trigger.dev with full Auth0 RBAC across 11 workspace roles.
What it does.
- Chat with AI personas representing demographic, psychographic, generational, or expert audience segments
- Stream AI-generated documents — reports, newsletters, email packs — into a full WYSIWYG editor with 40+ block types and inline editing
- Record meetings via Recall.ai bots that auto-extract highlights, action items, decisions, coaching metrics, and evidence-linked transcript spans
- Run focus groups with AI personas across 11 question types (NPS, Likert, semantic differential, ranking, matrix, and more) with aggregated insights and visualizations
- Analyze video content frame-by-frame for emotional, cognitive, behavioral, speech, and visual signals
- Subscribe to AI-curated news digests with persona-specific perspectives, scheduled by frequency, timezone, and topic
- Mave agent — branch conversations, track evidence, run web/KB tool calls, and visualize reasoning paths across Answer / Evidence / Timeline / Flagged tabs
- Export anywhere — DOCX, PDF, HTML, PNG, or Markdown — directly from the editor toolbar, chat artifacts, meeting analyses, or focus-group results
Inside the build.
Plate-Powered Editing Surface
A single Plate v44 editor instance powers two distinct surfaces: inline artifact editing in chat (artifacts parsed from <artifact> XML tags in streamed responses) and the full /generate template editor. 40+ plugins cover headings, tables, multi-column layouts, callouts, code with Prism highlighting, mentions, comments, equations, Excalidraw diagrams, embedded media, and AI/copilot commands. Auto-save runs through PlateEditorWrapper with 1s debounce, and serialization plugins handle DOCX import, Markdown round-tripping, HTML for email, and CSS inlining via Juice.
Structured AI Response Schema
Every chat response is a Zod-validated object: response text, optional editable artifact, emotion (valence/arousal), pragmatic (realism/actionability), biases array with severity, contextual factors, future considerations, confidence level, opinion spread, perspective shifts, and follow-up questions. The schema is enforced via generateObject() so every persona response stays analyzable and renderable in the UI without client-side parsing fallbacks.
Meeting Intelligence Pipeline
Recall.ai bots join Google Meet / Zoom calls, record audio + video, and emit transcripts. A Trigger.dev job (analyze-meeting, 25KB, concurrency 5) parses VTT/SRT, then runs structured AI extraction for: 7 highlight categories (KEY_INSIGHT, OBJECTION, COMMITMENT, QUESTION, RISK, OPPORTUNITY, ACTION_ITEM), priority-tagged tasks with owners and due dates, decisions with deadlines, transcript-span evidence linked back to every artifact, coaching metrics (talk ratio, question rate, interruptions, sales quality), and optional custom-schema extraction with 9 field types.
Mave Agent — Branched Research
Mave is a stateful research agent with conversation branching, evidence tracking, and tool execution. The orchestrator (mave-orchestrator.ts, 60KB) coordinates LLM calls, tool execution (Tavily search/extract, CircleMind KB queries, SEMrush, image/video generation), and branch management (mave-branches.ts, 20KB). Output is presented across four tabs — Answer, Evidence (citation-linked claims), Timeline (tool-call history), and Flagged — with per-thread persona attachment.
Multi-Tenant Workspace Topology
Account → Workspace → Project → Thread → Message hierarchy enforced via Prisma relations and middleware role checks. Each workspace owns its own brand voice, persona pool, integrations, dashboard layout (react-grid-layout JSON), budget alerts, knowledge base, and credit usage tracking (WorkspaceUsage daily aggregation, ProjectUsage per-project). Workspace types span USER, STARTER, PROFESSIONAL_AGENCY, ENTERPRISE, MARKETING_AGENCY, and BASIC_AGENCY.
Background Job Fleet (Trigger.dev v4)
9 background jobs run on Trigger.dev with prismaExtension and ffmpegExtension: meeting analysis (queue concurrency 5), video chunked frame analysis, focus-group response generation (concurrency 10), brand-voice extraction (concurrency 3), knowledge-base building via Perplexity + CircleMind, news-digest cron (every 30 min), multi-step onboarding workflow, and daily workspace analytics cron at 2 AM UTC (32KB job). Retries are exponential up to 3 attempts.
Edge Middleware + RBAC
middleware.ts runs on every protected request: Auth0 session check, public-route allowlist, invite-route bypass, subscription gate redirecting to /subscription, and dev-mode role injection. RBAC is matrix-based across 11 roles × task groups (FOCUS_GROUP, VIDEO_ANALYSIS, WORKSPACE, PROJECTS, CHATS, PERSONAS, ASSETS, WORKSPACE_SETTINGS, API_KEYS) and checked via isAllowed(role, permission, taskName) at every server action and API route boundary.
Export & Integration Surface
5-format export pipeline: DOCX via remark-docx, PDF via html2canvas + pdf-lib, HTML via Plate's HTML serializer with embedded styles, PNG via html2canvas, and Markdown via Plate's Markdown plugin — exposed from the editor toolbar, chat artifacts, generation outputs, meeting analyses, and focus-group results. The integrations layer (80KB) handles OAuth flows and data push to Slack (Block Kit), Linear, HubSpot, Salesforce, Asana, Monday.com, and Jira, plus Google Drive / OneDrive / Dropbox file pickers.
Under the hood.
- Plate (Udecode) v44 editor with 40+ plugins powering both chat artifacts and template generation, including AI commands, copilot autocomplete, slash commands, and DOCX/Markdown round-tripping
- Streaming response architecture using Vercel AI SDK (streamText, generateText, generateObject) with Zod-validated structured schemas covering emotion, biases, perspective shifts, and follow-up questions
- Trigger.dev v4 background workers (9 jobs) for meeting analysis, video chunking, focus-group generation, brand-voice extraction, knowledge-base building, news-digest cron, onboarding, and daily workspace analytics
- Hybrid auth + middleware: Auth0 Edge session validation, role-cookie injection, subscription gating, and invite-route bypass — all enforced before the App Router renders anything
- Multi-tenant data model: Account → Workspace → Project → Thread → Message hierarchy with workspace-scoped budgets, dashboards, integrations, brand voices, personas, and knowledge bases
- RBAC across 11 workspace roles (OWNER, ACCOUNT_ADMIN, ADMIN, DEPARTMENT_ADMIN, ACCOUNT_MANAGER, MANAGER, EDITOR, ANALYST, CREATIVE_SPECIALIST, VIEWER, CLIENT_VIEWER) checked via permission matrix per task group
- OAuth integration layer (80KB single file) for Google Drive, OneDrive, Dropbox, Slack, Linear, HubSpot, Salesforce, Asana, Monday.com, and Jira with automatic token refresh
- Multi-stage Dockerfile, GitHub Actions pipelines for dev/prod, ECR push, and 95+ environment variables wired through the CI secrets
The toolkit.
Persona Chat
Stream chat with pre-built or custom personas, including MCDA-weighted custom personas with localization and purpose packs
Generation Apps
Database-driven template grid with dynamic input fields, brand-voice injection, and AI streaming directly into the Plate editor
Meeting Bots
Recall.ai bots that join meetings, transcribe, then extract highlights, tasks, decisions, coaching metrics, and evidence
Focus Groups
Stripe-billed AI research sessions with 11 question types and aggregated insights across configurable sample sizes
Video Analysis
S3-backed chunked frame extraction with multi-modal AI scoring across emotional, cognitive, behavioral, speech, and visual axes
News Digests
Scheduled persona-aware news digests via Perigon, delivered through Resend with React Email templates
Mave Agent
Branched research agent with tool execution, evidence tracking, and Answer/Evidence/Timeline/Flagged views
Schema Marketplace
Custom meeting-extraction schemas with 9 field types, publishable for community sharing and reuse
Integrations Push
One-click push of meeting outputs and tasks to Slack, Linear, HubSpot, Salesforce, Asana, Monday.com, and Jira
What I learned.
- Drawing the Plate editor as a single shared surface for both inline chat artifacts and the standalone generation editor avoided two separate editor stacks and kept formatting consistent across exports
- Zod-validated structured AI response schemas produced predictable analytics fields (emotion, bias, confidence, perspective shifts) that the UI could render without parsing fallbacks
- Splitting heavy work onto Trigger.dev (9 jobs) with concurrency limits per queue kept the Next.js request path fast while still giving meeting/video/focus-group flows minutes of runtime when needed
- Modeling the workspace as the single tenancy unit — owning budgets, brand voice, personas, integrations, dashboards, and KBs — made cross-feature data access clean and made RBAC enforcement uniform across 11 roles
- Centralizing every OAuth integration in a single 80KB actions file with shared token-refresh helpers prevented per-integration drift across Slack, Linear, HubSpot, Salesforce, Asana, Monday, Jira, Drive, OneDrive, and Dropbox
- Edge middleware was the right place to enforce auth + subscription + role injection; pushing those checks down into pages or actions duplicated logic and broke invite/share flows