Lunaria
2026Pre-Production · Live for B2BDocument management platform with AI-powered semantic search. Upload documents, ask questions in plain English, and get synthesized answers grounded in your own content — across multi-tenant workspaces with fine-grained access control. Solves the "where did I see that" problem for teams drowning in PDFs, scanned contracts, and Google Drive folders by combining OCR, Graph RAG over SurrealDB, and natural-language Q&A with citations.
Case Study
Overview
Lunaria is a document management platform built around three pillars: ingest anything (uploads, Google Drive sync, scanned images with OCR + semantic chunking), find anything (Nova — natural-language search powered by Graph RAG over SurrealDB, plus hierarchical tags, saved views, favorites, recents), and share safely (workspace-scoped multi-tenancy, plan-aware RBAC, public portal links with bearer tokens, full audit trails). The system is polyglot — a Nuxt 3 frontend talking to a NestJS 11 backend that delegates layout-aware OCR to a Python FastAPI sidecar running IBM Docling + EasyOCR. Documents land in S3, get extracted into semantic chunks, and are ingested into a SurrealDB knowledge graph so search traverses entity relationships rather than raw cosine similarity. The dev environment ships as a single docker compose up with seven services orchestrated for full prod parity, and the test suite covers 290+ Vitest + Playwright tests with persistent auth fixtures.
What Makes It Special?
For Users
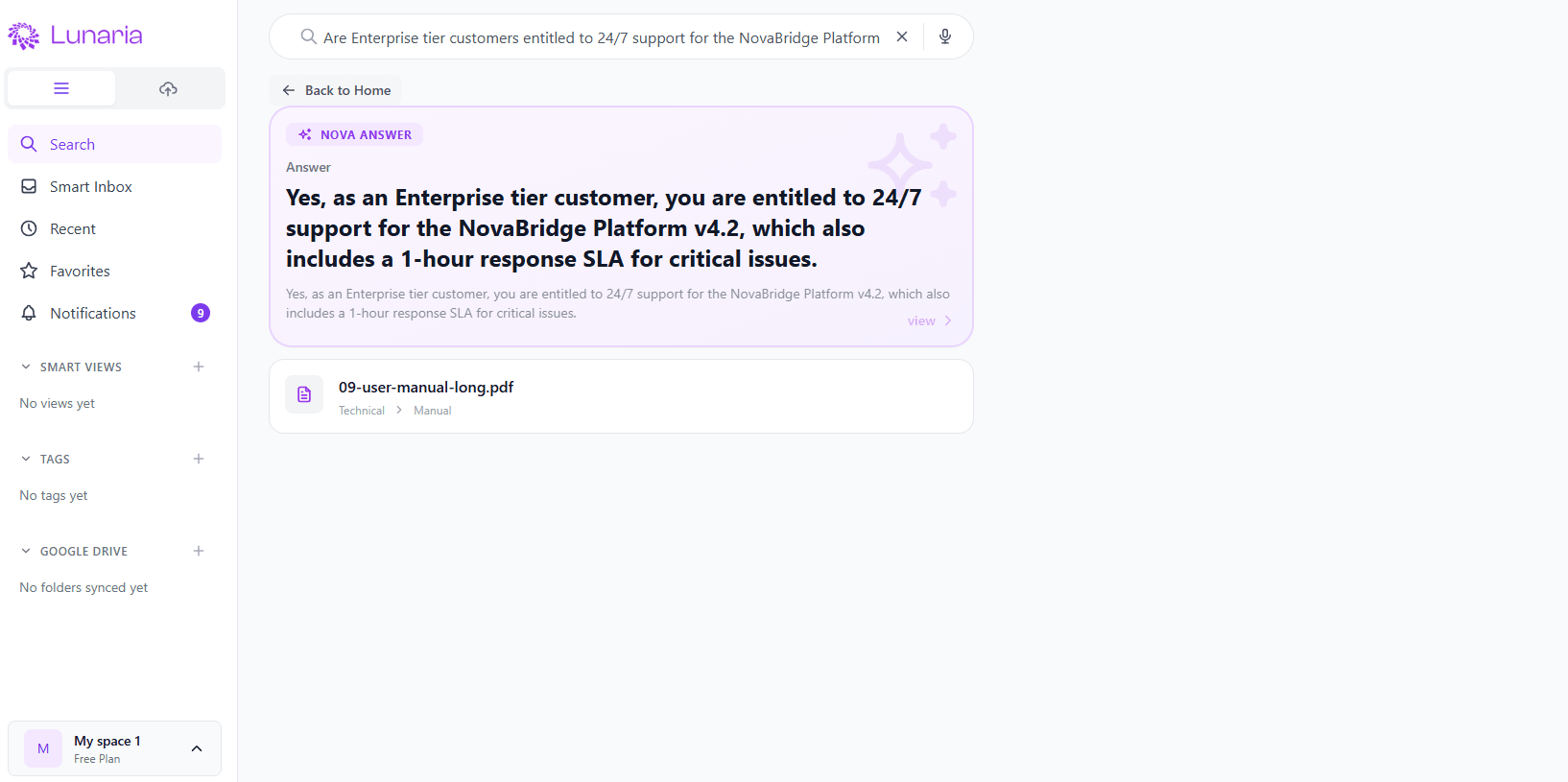
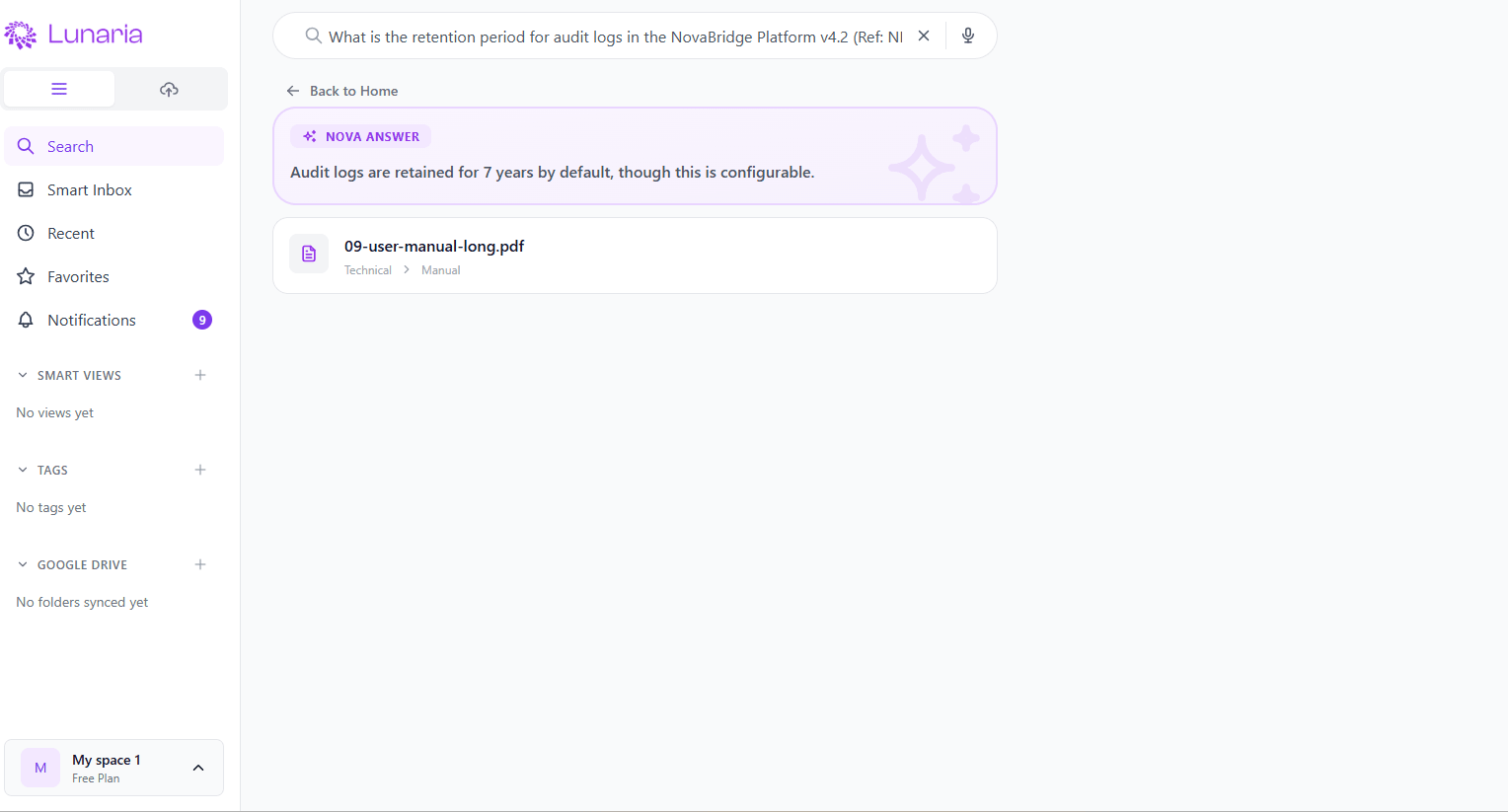
- •Ask plain-English questions like "what's the renewal clause in the Acme contract" and get synthesized answers with source citations — not a list of keyword hits
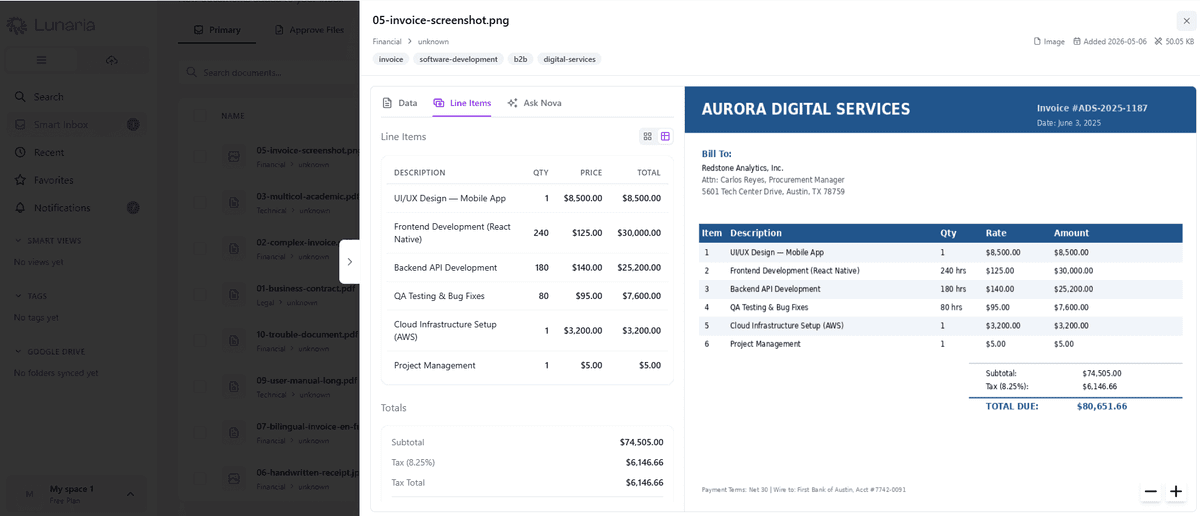
- •Upload PDFs, scanned images, and contracts; OCR makes every page queryable so knowledge buried in image-based files becomes searchable
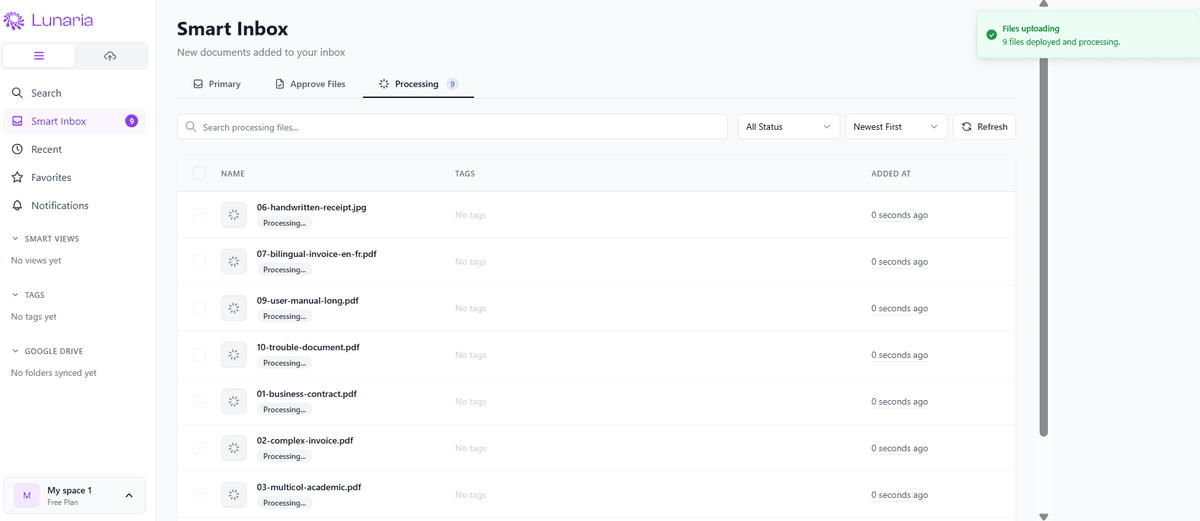
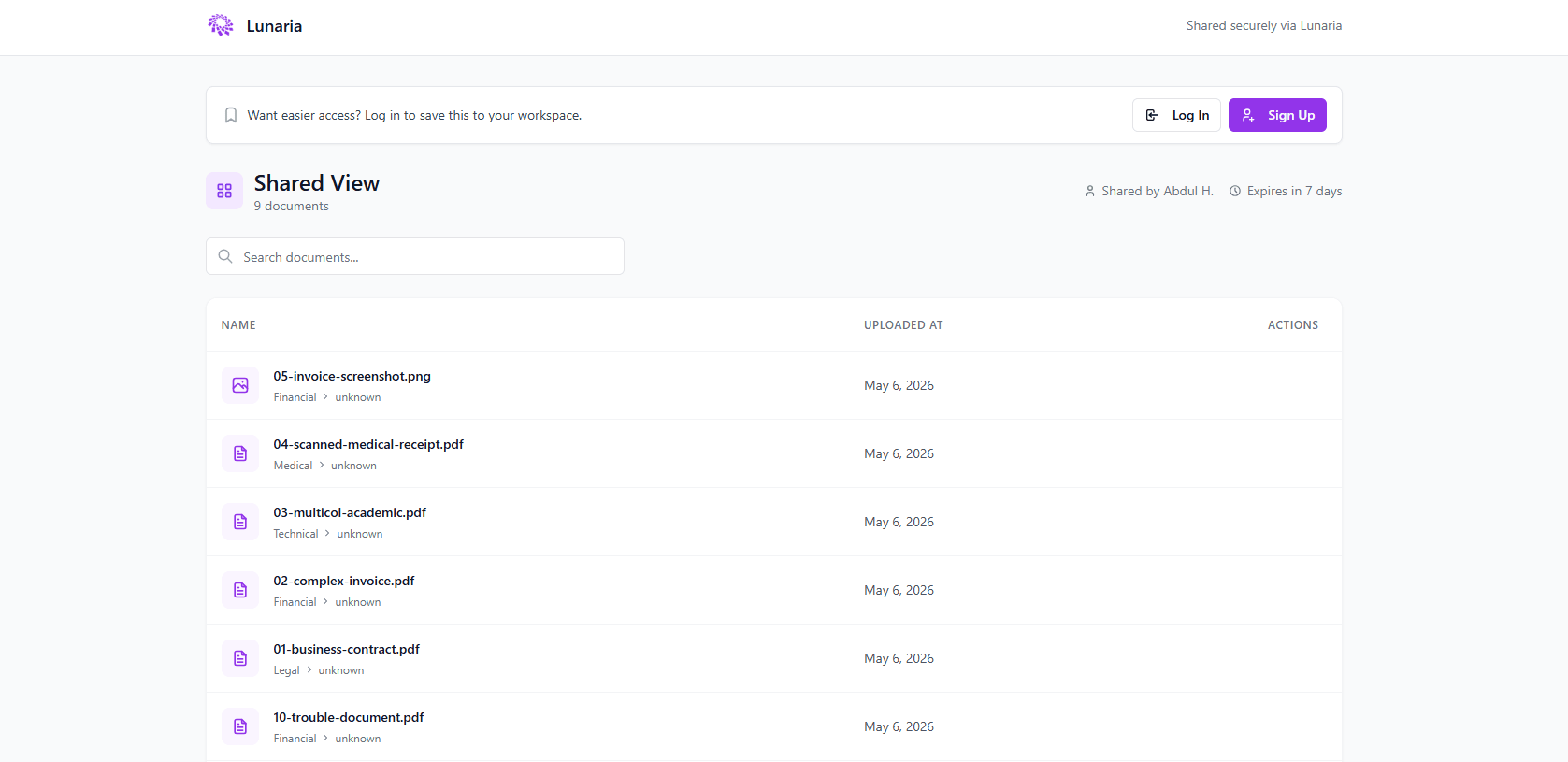
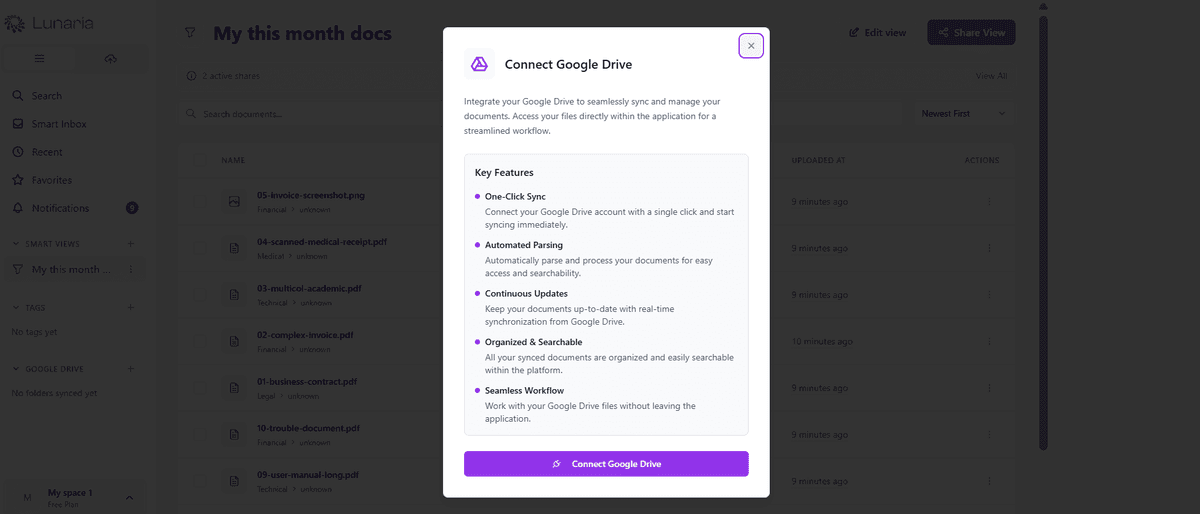
- •Sync Google Drive folders directly with auto-import and per-file processing status, so existing document hoards become organized without moving originals
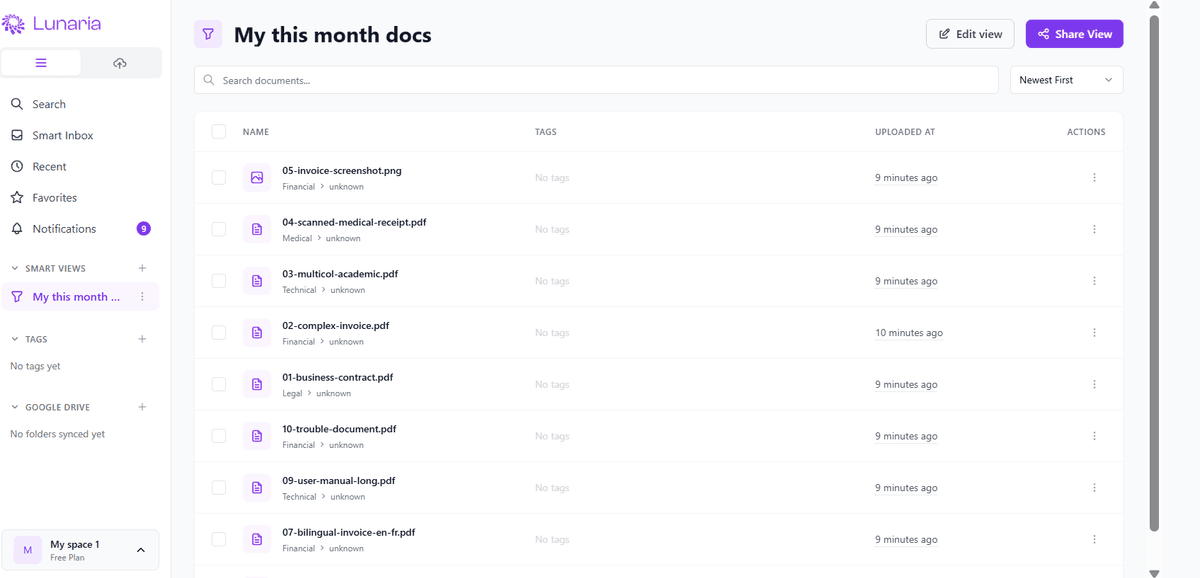
- •Organize with hierarchical tags, saved views, favorites, recents, and a 30-day soft-delete trash with restore
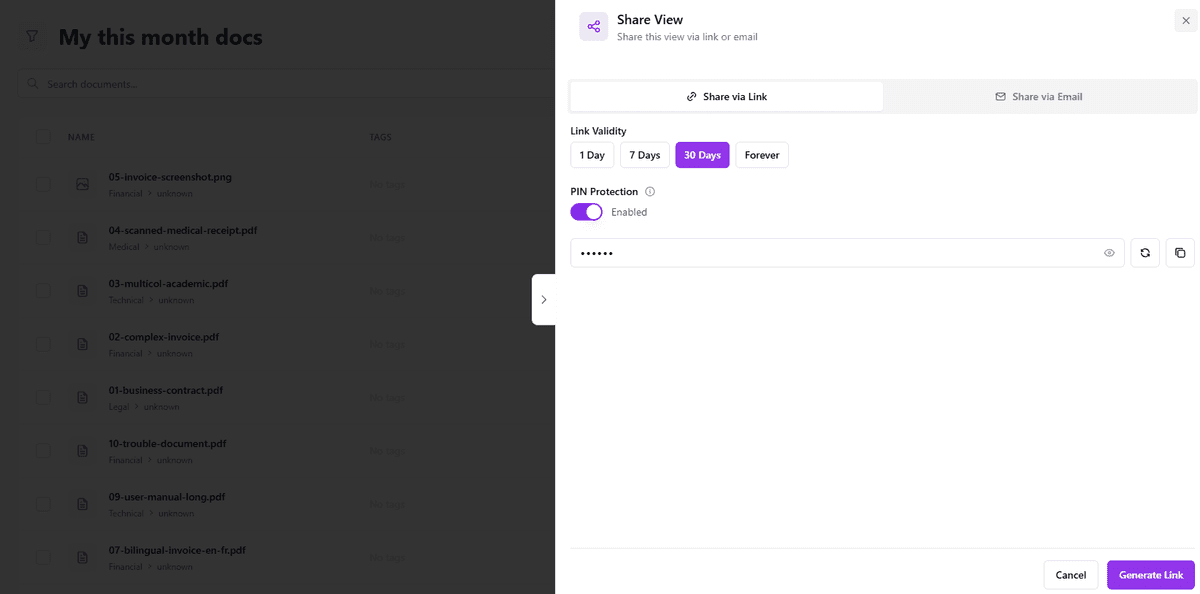
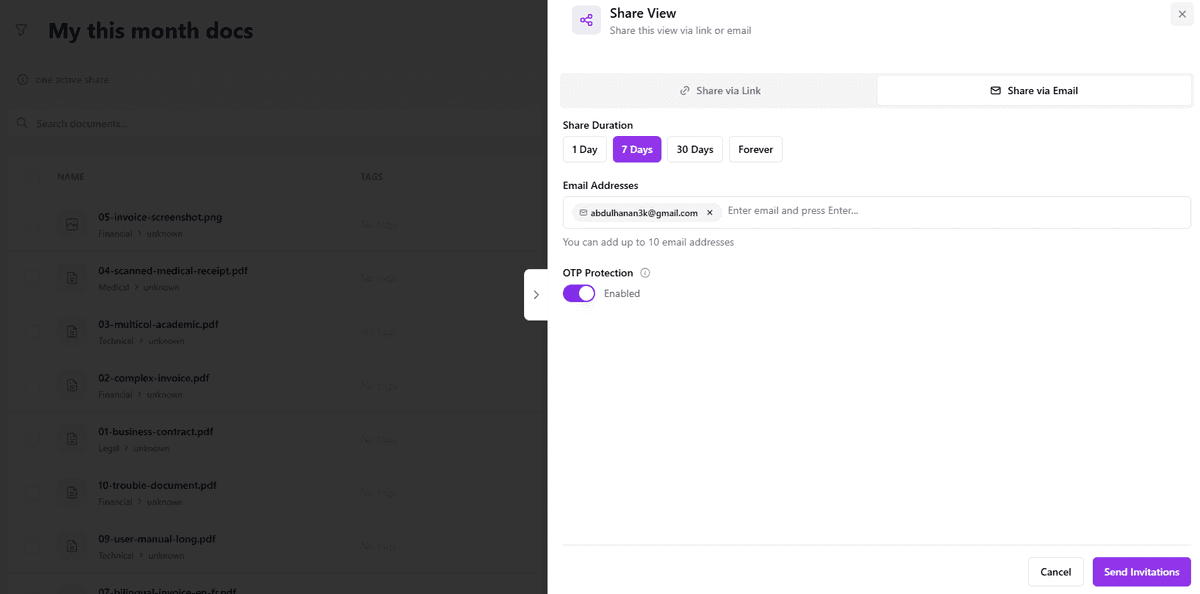
- •Share documents externally via bearer-token portal links with expiration and scoped permissions instead of risky email attachments
- •Real-time notification stream for uploads, shares, and mentions via Server-Sent Events with an in-app inbox
- •Multi-workspace switching (`x-workspace-id` header) so users can belong to many orgs while keeping data scoped
- •Quota-based AI entitlements with color-coded warnings (ok / warning at 80% / critical at 90% / exceeded) and graceful upgrade prompts
For Developers
- •Polyglot service boundary — Python FastAPI sidecar (Docling + EasyOCR + HybridChunker) handles layout-aware OCR over HTTP, keeping the Node backend lean and letting each side scale independently
- •Graph RAG over SurrealDB instead of a vector DB — semantic knowledge graph linking entities across documents enables multi-hop questions (e.g. "contracts mentioning vendors based in Germany")
- •Plan-aware RBAC: `resolveEffectiveRole()` clamps Admin → Member capabilities on free / family / plus plans, plus a pyramid rule preventing role escalation; CASL ability factory + PermissionsGuard + @RequirePermissions() enforce per-resource permissions
- •Workspace-scoped middleware filters every Prisma query by `x-workspace-id` so cross-tenant data leaks are structurally impossible without an explicit override
- •Event-driven backend via EventEmitter2 — `user.created`, `document.uploaded`, `document.processed` keep audit logging, notifications, and Drive sync as @OnEvent listeners instead of direct service imports
- •Three-tier frontend API layer: $fetch plugin (auth + workspace headers + global 401 handling), useAPI composable, domain modules — single point for header injection, trivially mockable in tests
- •i18n at scale — lazy per-feature locale JSON, browser-language detection, `[T]` test locale that surfaces missing translations to QA, and i18n-aware Yup validation schemas
- •Single `docker compose up` brings Postgres + Redis + LocalStack (S3 + DynamoDB + Secrets) + SurrealDB + MailHog + Docling + app online with prod parity, no AWS credentials required
- •290+ tests across Vitest (happy-dom) + Playwright with factories, mount helpers, persistent auth state, and a PLAYBOOK.md onboarding doc
Architecture Highlights
Document Processing Pipeline
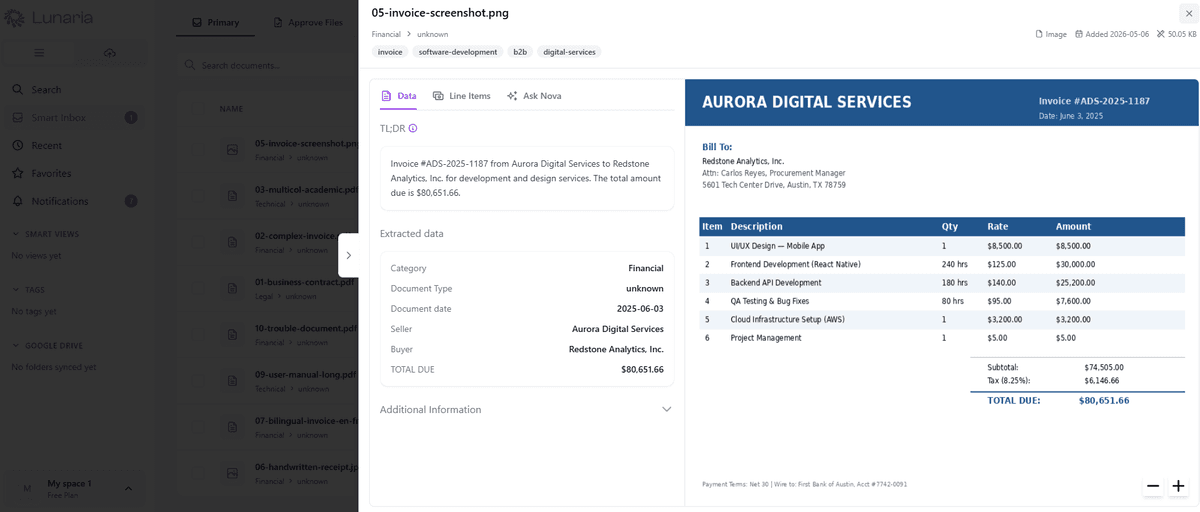
Upload hits the NestJS backend → file persisted to S3 (LocalStack in dev) → BullMQ enqueues an extraction job → worker forwards the file to the Python docling-service over HTTP → Docling runs EasyOCR + HybridChunker and returns markdown plus semantic chunks → chunks ingested into the SurrealDB knowledge graph → Gemini-backed extraction pulls structured data when applicable → AiTokenUsage table tracks per-workspace LLM spend for billing.
Graph RAG Over SurrealDB
Instead of dumping embeddings into a vector DB, Lunaria builds a knowledge graph in SurrealDB linking entities across documents. Search traverses the graph for relationship-aware retrieval, which outperforms pure cosine similarity on multi-hop questions where the answer requires connecting facts across multiple documents.
Workspace Context Middleware
WorkspaceContextMiddleware extracts `x-workspace-id` from every request, validates membership, and injects the context into the request lifecycle. Every Prisma query is then workspace-filtered automatically — making cross-tenant data leaks structurally impossible without an explicit, audited override.
Plan-Aware RBAC
Three roles (Owner / Admin / Member) plus a `resolveEffectiveRole()` clamp that downgrades Admin capabilities to Member on free / family / plus tiers. A pyramid rule prevents granting roles higher than your own and prevents modifying peers of equal or higher rank. CASL's @casl/ability and @casl/prisma plus a PermissionsGuard and @RequirePermissions() decorators enforce permissions per resource.
Polyglot Service Topology
Three runtimes by design: Nuxt 3 frontend deployed on Vercel, NestJS 11 backend on a Node runtime with PostgreSQL + DynamoDB + SurrealDB + Redis behind it, and a Python 3.11 FastAPI docling-service running as an ECS Fargate task in a private VPC. The service boundary keeps OCR's heavy Python deps off the Node hot path and lets each tier scale independently.
Event-Driven Module Communication
Modules talk via EventEmitter2 rather than direct service imports. Domain events (`user.created`, `document.uploaded`, `document.processed`) are consumed by @OnEvent listeners that handle audit logging, notifications, and Google Drive sync — keeping cross-cutting concerns from polluting core domain code and making it trivial to add new listeners without touching publishers.
Soft Delete + 30-Day Trash
Every major entity carries `isDeleted` / `deletedAt` / `deletedBy` columns plus an `originalLocation` JSON field that snapshots the entity at delete time. A TrashItem table tracks the restore deadline; TrashService.restore() rebuilds within the 30-day window. The snapshot approach means restores work even if the surrounding hierarchy has changed since the delete.
Three-Tier Frontend API Layer
plugins/api.js exposes a $fetch instance with auth + workspace headers and global 401 handling; composables/useAPI.js wraps useFetch reactively; api/ holds domain modules like EntitlementsAPI.getEntitlements(). Clean separation makes header injection a single concern, mocking trivial in tests, and prevents API logic from leaking into components.
Feature Gating Subsystem
Entitlements are fetched on app boot into a Pinia store; useQuota().canUse('LUNARIA_AI_CREDITS_PER_MONTH') gates UI affordances; the server independently enforces hard limits so the client can't be bypassed. Color-coded quota status (ok / warning 80% / critical 90% / exceeded) drives consistent UX across upgrade prompts and progress bars.
Integrated Tools
Nova Search
Natural-language Q&A over your documents with synthesized answers, source citations, suggested questions, and saved searches
Document Ingestion
Multi-file drag-and-drop upload, Google Drive folder sync, OCR for scanned images, and inline PDF/image preview with metadata sidebar
Tags & Views
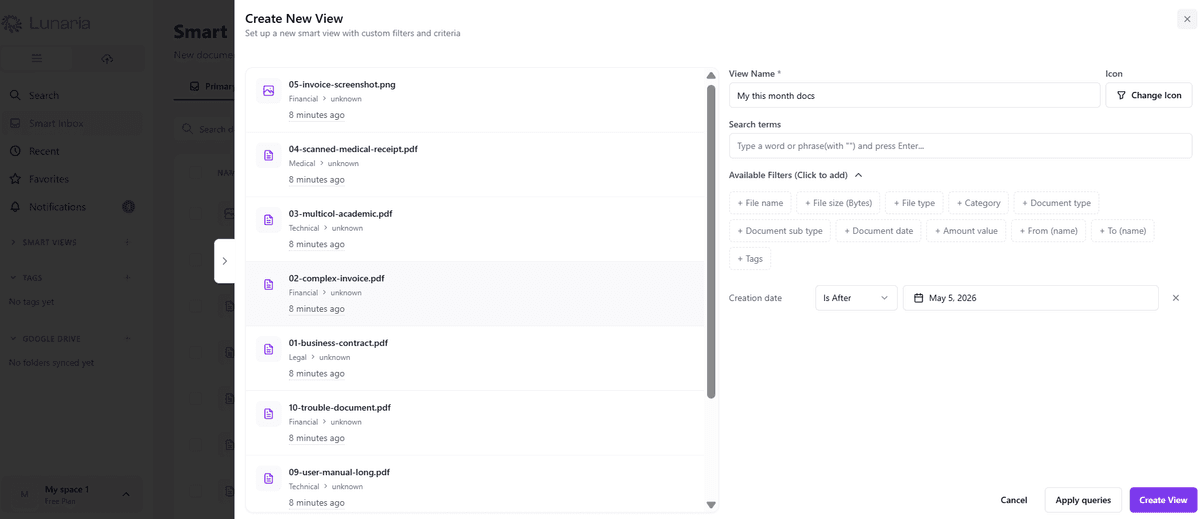
Hierarchical tags with drag-to-nest, saved views (filtered collections), linked views (multi-criteria filters), favorites, and recents
Google Drive Integration
OAuth-based account linking, folder-level auto-sync, and per-file processing status via LensGoogleDriveFileLog
Portal Sharing
Public portal links with bearer tokens, configurable expiration, scoped permissions, and read-only guest mode
Real-Time Notifications
Server-Sent Events stream powering an in-app inbox plus toast notifications for uploads, shares, and mentions
Multi-Tenant Workspaces
Per-request workspace switching via `x-workspace-id`, member invitations, ownership transfer, and Teamspace → Group sub-organizations
Quotas & Entitlements
Quota-aware UI with server-enforced hard limits, color-coded status (ok / warning / critical / exceeded), and graceful upgrade flows
Audit Trail
Per-document activity log of views, downloads, and shares with full audit history
Key Learnings & Challenges Solved
- 1Drawing the service boundary at OCR — a Python FastAPI sidecar over HTTP — kept heavy ML deps off the Node hot path and let the OCR tier scale independently of the API tier
- 2Graph RAG on SurrealDB beat raw vector search on the questions users actually asked, because the high-value queries were multi-hop (connect a vendor's country to a contract's renewal date) rather than single-document semantic matches
- 3Workspace-scoped middleware that filters every Prisma query made multi-tenancy structurally safe — accidental cross-tenant access required an explicit, reviewable override rather than a forgotten WHERE clause
- 4Plan-aware role clamping with `resolveEffectiveRole()` kept RBAC simple — three roles in code plus a tier-aware downgrade — instead of exploding into a per-tier role matrix
- 5Event-driven cross-cutting concerns (audit, notifications, Drive sync) via EventEmitter2 + @OnEvent kept domain modules clean and made adding new listeners a non-invasive change
- 6A single `docker compose up` covering Postgres + Redis + LocalStack (S3 + DynamoDB + Secrets) + SurrealDB + MailHog + Docling gave new contributors prod-parity dev environments without AWS credentials
- 7Treating feature gating as a first-class subsystem (Pinia entitlements store + useQuota composable + server-side enforcement + color-coded UX) prevented quota logic from being scattered across components
- 8An i18n `[T]` test locale that visibly prefixes every translated string surfaced missing keys to QA before they reached users — much cheaper than waiting for translator feedback